paper-reading, code&rl方向
Effi-code: Unleashing code efficiency in language modelsSWIFTCODER: Enhancing Code Generation in Large Language Models through Efficiency-Aware Fine-tuning
问题:以前的方法主要关注正确性忽略效率(effibench,gpt4 代码执行时间是标准解决方案的1.69与45.49倍(avg, worst))
衡量效率:本地测量执行时间和内存
具体来说是三个指标:
- 执行时间ET
- 最大内存使用量MU
- 总内存使用量TMU
这篇论文并没有用RL的方法去激发LLM生成更高效率代码的能力,而是”优化“训练数据集的代码效率,并证明了训练集代码效率高也会让LLM生成更高效率的代码(ET 的相关性为 0.972,MU 的相关性为 0.950,TMU 的相关性为 0.986)
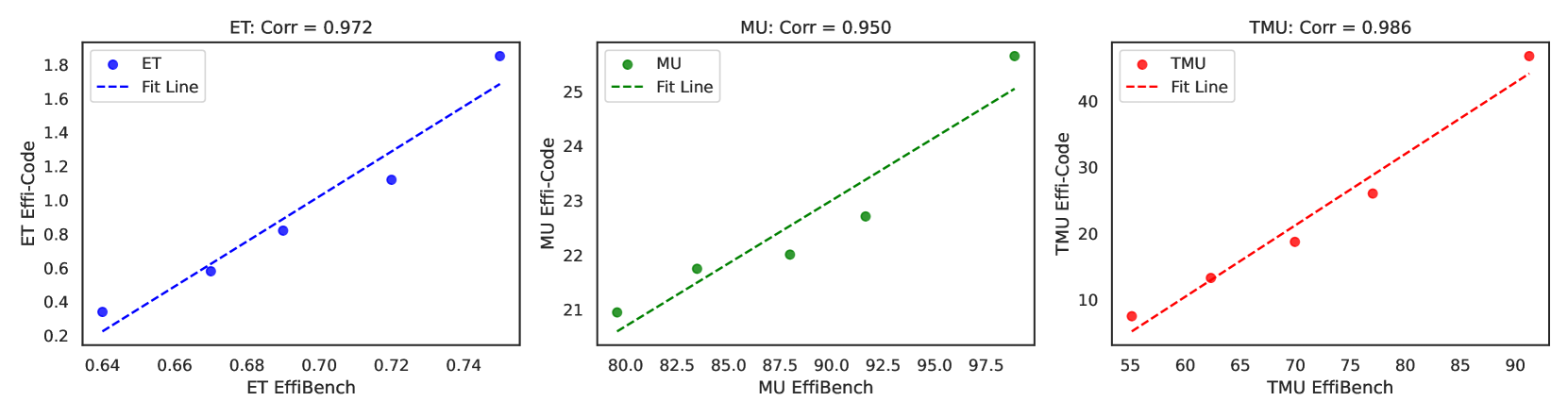
效果:qwen2.5-coder-7b-instruct pass@1 44.8 -> 57.7,正确任务的执行时间减少48.4%
方法:构建代码生成数据集,进行微调

具体来说,先拉下来开源数据集,过滤一遍后,直接让更强的LLM生成更好的解决方案,�然后本地跑一遍得到效率
不同效率的代码示例 
文章认为的效果提升来源:
- 多语言数据集
- 数据准备阶段过滤充分
- 数据量(有超过 70,000 个训练示例,比先前的mercury 1.8k要大很多)
简评:大体上感觉是工作量密集型的工作,比如finetune多个llm和在多个数据集上进行相关评测,但方法上并没有创新之感,洗的数据是高效率代码的自然输出的结果效率也会变高,并不令人感觉新奇,只是讲好了我们需要同时看重代码质量(这里是效率)这一指标的故事
EffiBench: Benchmarking the Efficiency of Automatically Generated Code
问题:现在衡量代码正确性的文章已经有很多了,但是兼顾正确和效率的相对少
如果要考虑效率的话,一个问题是原先的代码数据集的任务太简单了,很难区分效率;同时很多任务也不是效率密集型的,并且效率相关的测试也不够
数据集构建:leetcode
“标准解决方案”: stackoverflow最多star/leetcode top answer
测试用例:LLM生成
简评:典型的benchmark工作
Diversity-Aware Policy Optimization for Large Language Model Reasoning
问题:diversity在reasoning能力中扮演重要角色,但缺乏定量的研究
动机:传统RL认为,多样性有助于策略探索(例如,SAC等算法),帮助跳出局部最优、加速训练收敛,但对于LLM呢?
方法:
直接增加熵,长度bias, 较长的响应 -> 引入token level diversity
tradeoff 质量和多样性 -> 仅对正样本用多样性增强,确保以性能标准为主导
贡献:
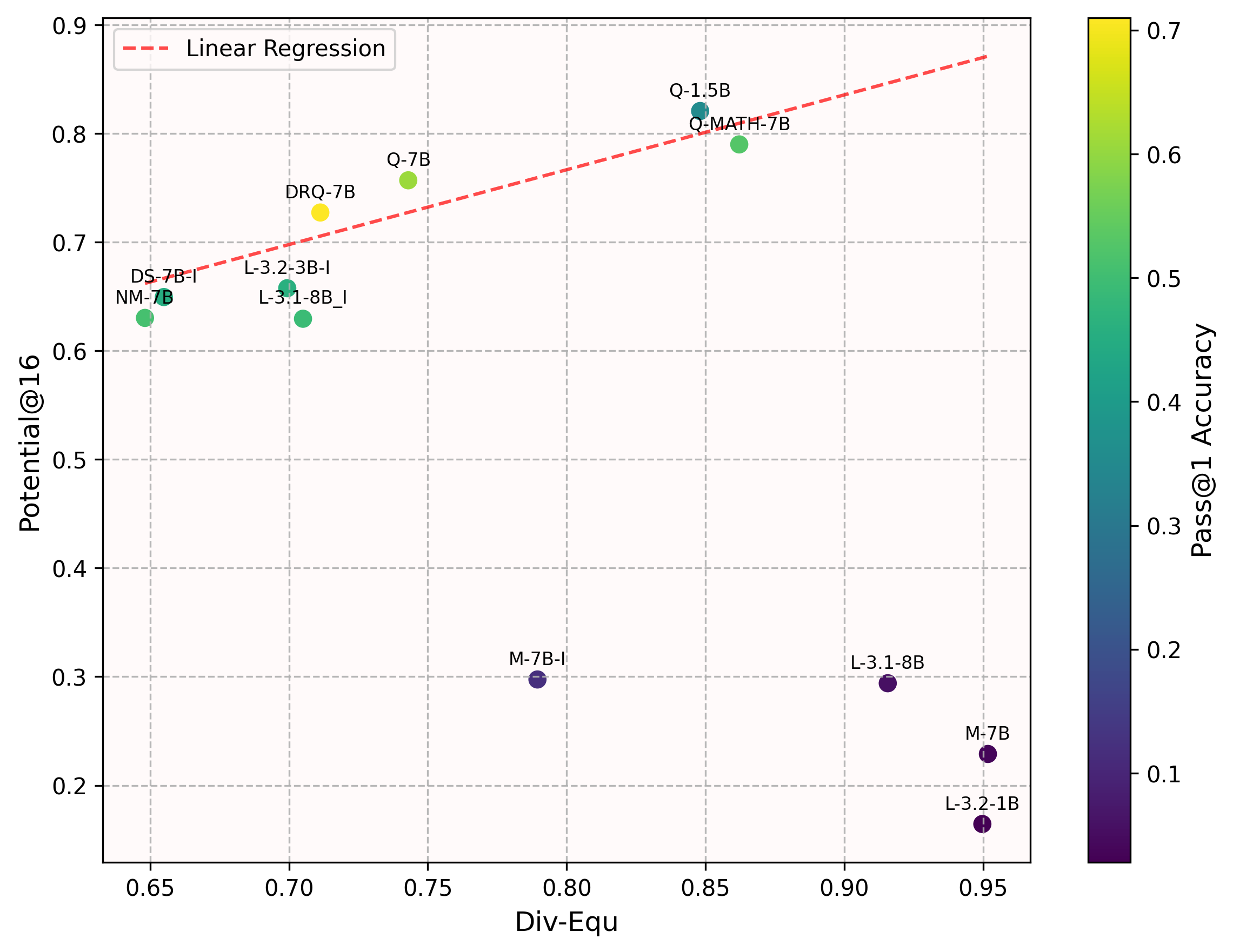
- 多样性的Potential@k指标和LLM reasoning存在正相关关系
- token-level diversity objective, selectively applied to positive samples
奖励:和R1一致,acc reward和format reward,前者和ground truth 比较,后者让答案以 \boxed{}格式呈现
多样性度量:response中不同方程的比例
其中,U是k个采样中的独立方程数量,A是总方程数量
Potential@k: 衡量模型在第一次失败后,在k次(k=16 in paper)内纠正答案的能力
(为啥定义这样一个指标?这个分子分母分别求和挺怪异的,也不是类似条件概率的算法)
结果:对于推理能力有限的LLM(Pass@1<0.4) 多样性和Potential@k没什么关系,但对于更好的LLM,就有明显的正相关关系
定义的token-level熵
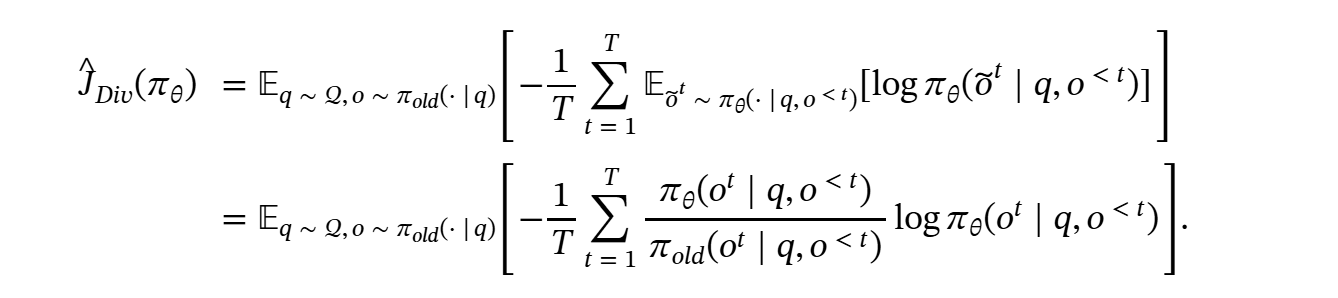
在实测中,作者发现直接把这个熵带入训练会增强错误样本的多样性,相当于对错误样本做增强,因此打了只对正样本做的补丁
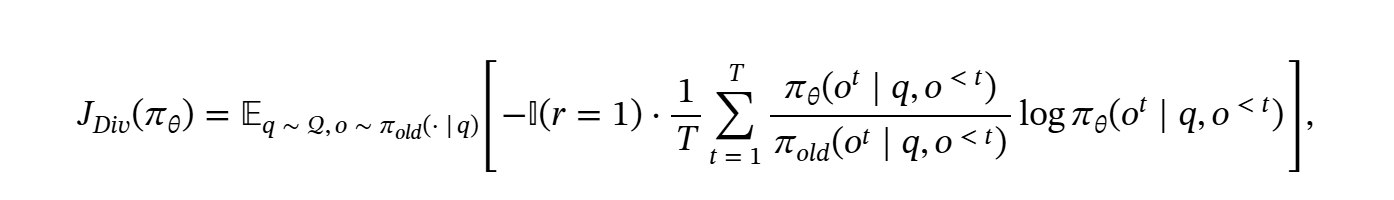
而对这个式子求导能直观感受到多样性的部分
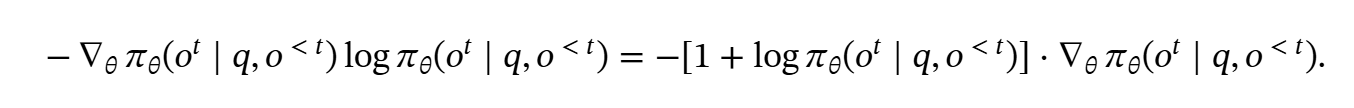
对于大多数token, 采样概率的值都是小于的,则前一个乘项小于0 ,熵的梯度和采样概率的梯度成正相关,熵增有利于对稀有Token的采样
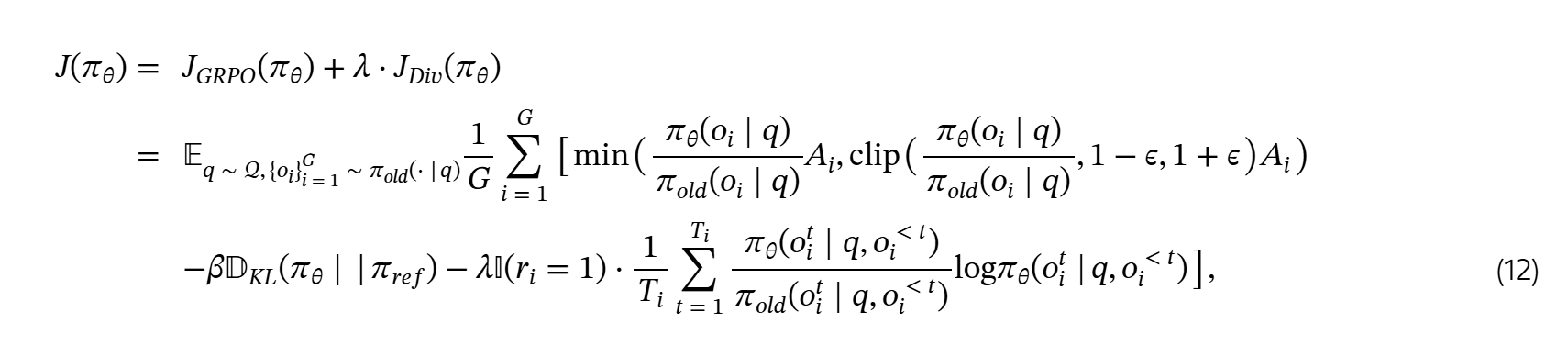
实际取
简评:
动机非常清晰,实验也比较充分,展示了虽然是 well-known 的需要基模能力达标多样性才有意义的结论。
对于LLM优化目标的改造的说明是合理的。理论说法是GRPO带来的更新依赖于组内样本的差异,(因为是用std/mean来计算优势函数A),所以增强多样性能避免优势消失带来的一些问题,本质上是在避免 里面的 过小导致不稳定的问题
只对正样本应用多样性损失的trick也是有意义的。
但衡量多样性的时候比较草率,首先是局限在数学范围,其次感觉 方程多样性 != 解法多样性,所以多样性指标总感觉欠说服力。
他们自己也在文章中说:"许多现实世界的应用需要用户意图的多样性(例如,需要数学问题的代数和算术解,或者生成具有不同算法方法的代码), 这样的多样性不等于token level的多样性"
Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning
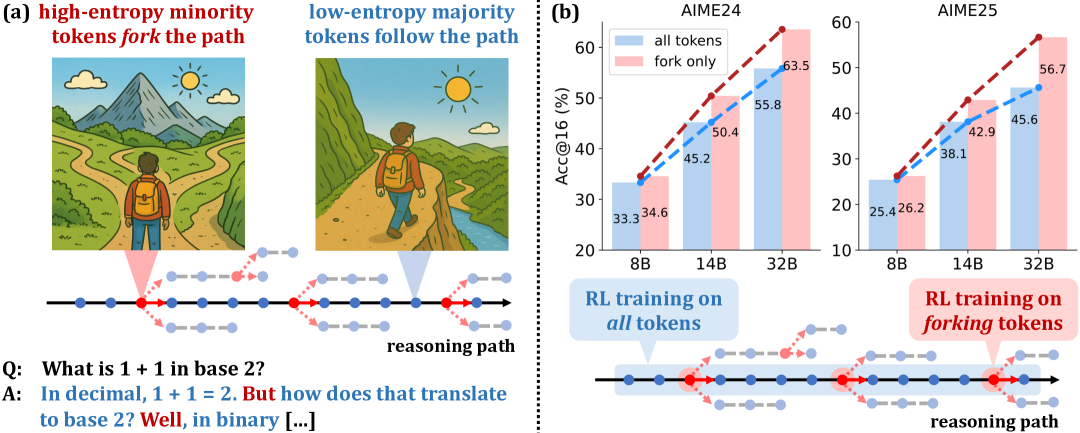
问题: 现有RL for LLM算法对不同的token一视同仁,没有考虑token自身的异构性
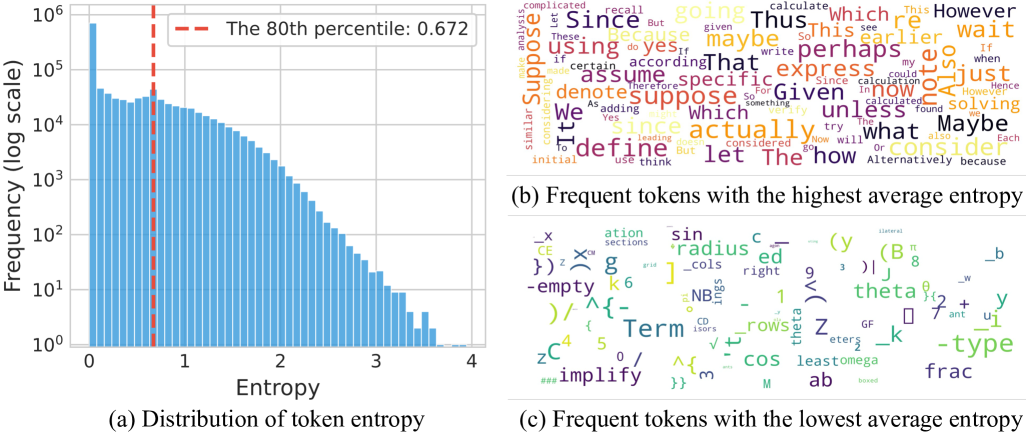
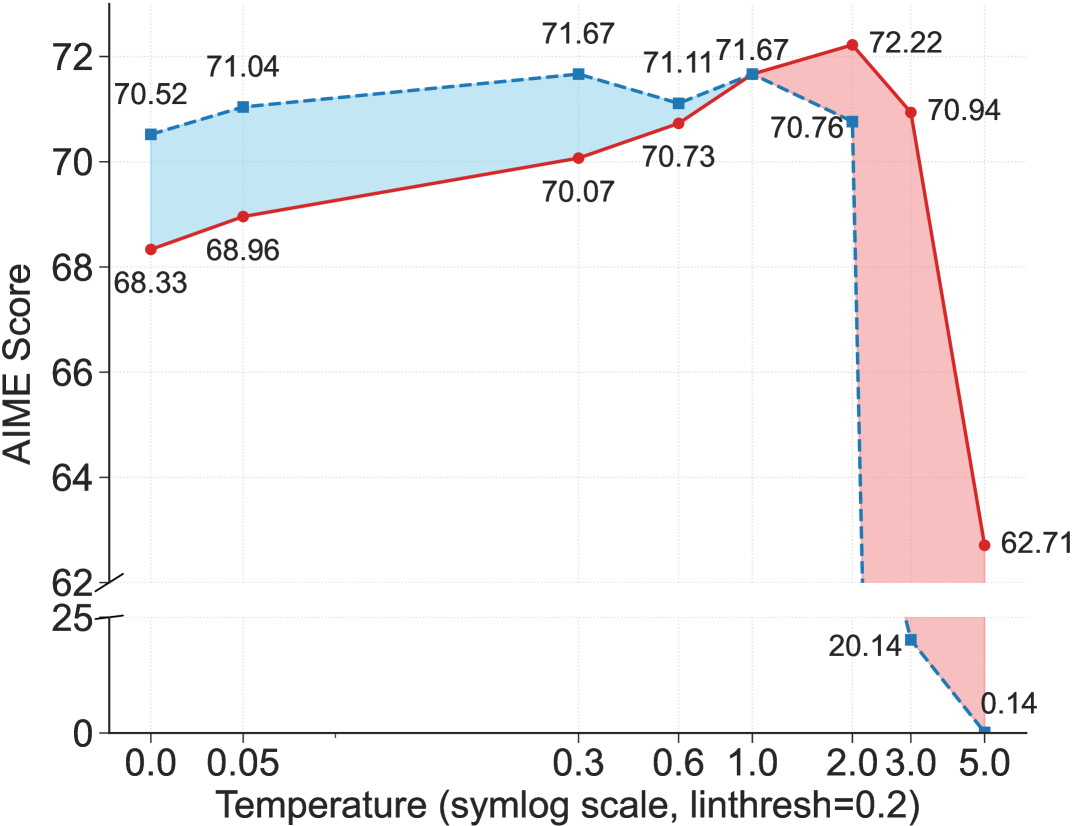
观察: 低熵token主要决定语言结构,高熵token则作为关键的决策点。手动调整forking token的熵,适度增加这些token的熵可以显著提升推理性能,降低熵会导致性能下降。
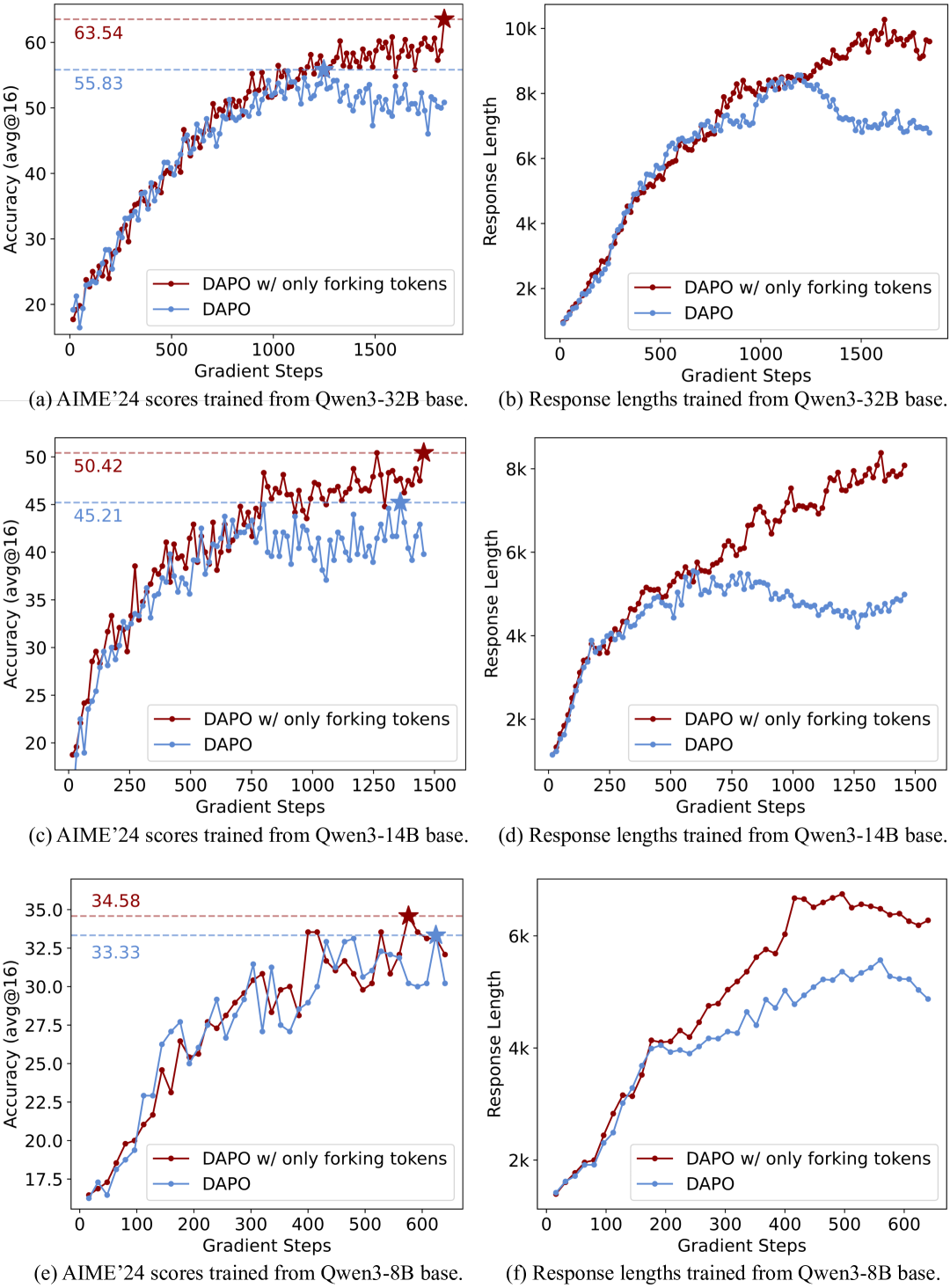
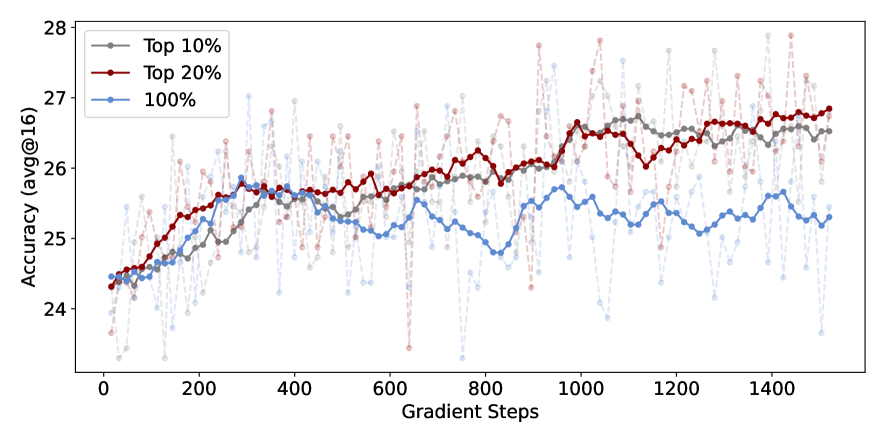
仅保留20% token的策略梯度更新,剩下的mask掉,性能上能和全量媲美甚至超越,在RL过程中,只有一小部分高熵 token 对探索有实际贡献,而其他 token 则可能中性甚至有害
20%是实验得到的最优比例
另一个发现是32B的性能提升大于14B大于8B
熵定义:
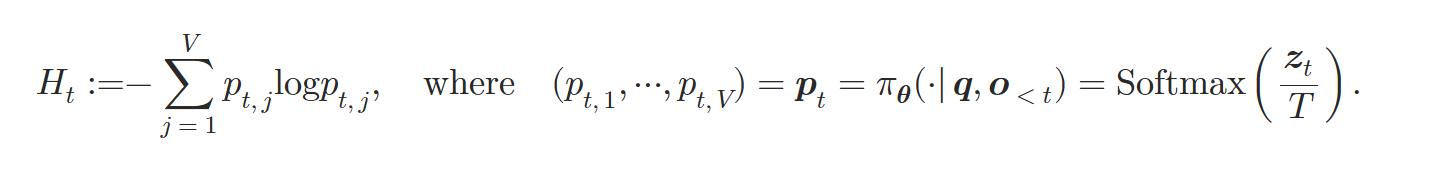
一个很直观的分布图,高熵Token基本是重要的转折词,而低熵token是一些前后缀等
另一个稍微不直观的图
可以得到的结论是高熵token配合高温度能够得到好性能,而低熵token在不同温度下都不太影响最终效果
作者还发现,RLVR的过程基本就是这些高熵token的熵改变的过程,低熵Token的熵相对稳定,初始熵较高的 token 在 RLVR 后往往会经历更大的熵增。
而只对高熵Token进行RLVR能得到更好的效果
甚至作者在OOD数据(代码数据)上进行评测,发现高熵的token选择后,泛化性也更好
讨论:
- RL倾向于保持高熵令牌的熵,而SFT倾向于将输出推向one-hot,降低熵,作者表示这可能是RL更能泛化而SFT容易记忆、难以泛化的原因
- 传统RL假设一整条轨迹上的熵是接近均匀分布的,这对LLM不成立
- LLM RL中,之前常用的熵损失鼓励探索可能未必适用,因为可以是低熵token的熵增也可能是高熵token的,而DAPO的clip higher能筛选出高熵token,即重要性比率ratio()更高的token通常对应高熵token,这呼应了前文中,RLVF对高熵token的熵值有较大改变
简评:开始的手动把熵调高感觉等价于把奖励调高等价于数据增强,作为一种RL trick细想并不惊奇,是稀有样本情况下的常用技术
从这个角度继续往下想,如何理解这个多数token对训练甚至有害呢,感觉也是能合上现有对LLM RL的state定义不太合理,或者说探索空间太大,采样样本太少,不可能得到正确的Q函数,导致对于一些本来就很无所谓的token,更新的方向也是比较盲目
总之,这篇文章实验非常充足,分析也比较到位,效果也十分亮眼,确实是在当前的SOTA上往前推进的好文章
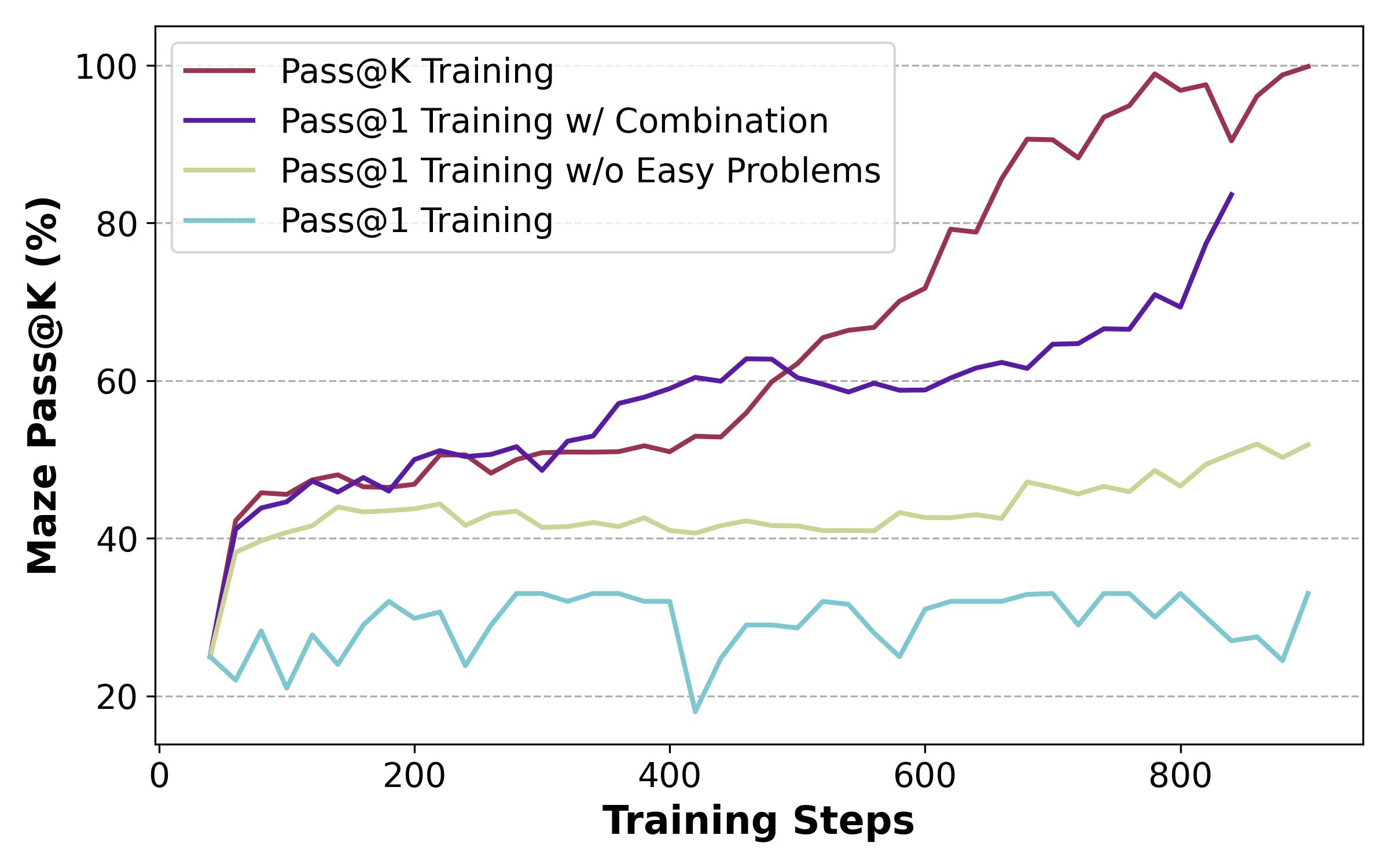
Pass@k Training for Adaptively Balancing Exploration and Exploitation of Large Reasoning Models
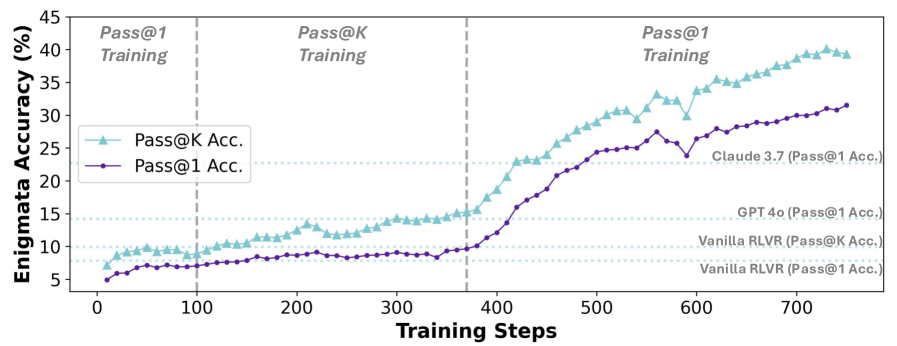
问题:RLVR 通常采用 Pass@1作为奖励,但容易收敛到局部最优;Pass@k则常用于验证,本文用Pass@k直接作为训练,并设计了对应的优势函数,发现效果比Pass@1更好(更高的Pass@k分数,保持的Pass@1分数)
Pass@1 收敛到局部最优的问题在于正向奖励的探索可能路径太长,模型会倾向于利用而不是探索
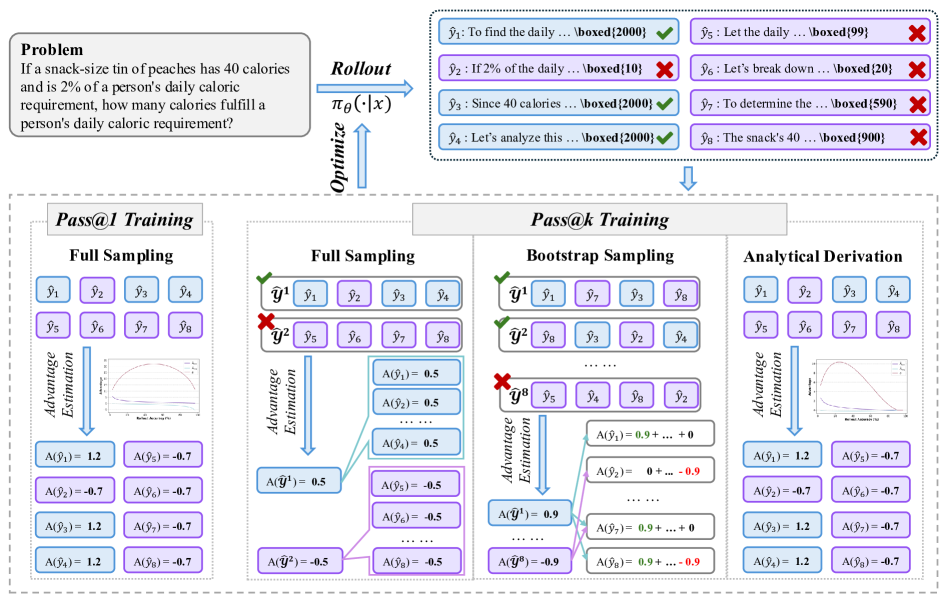
方法:
-
Full Sampling: 每组采样的k个rollout计算奖励,之后整组的奖励由每个rollout的最大值给出
-
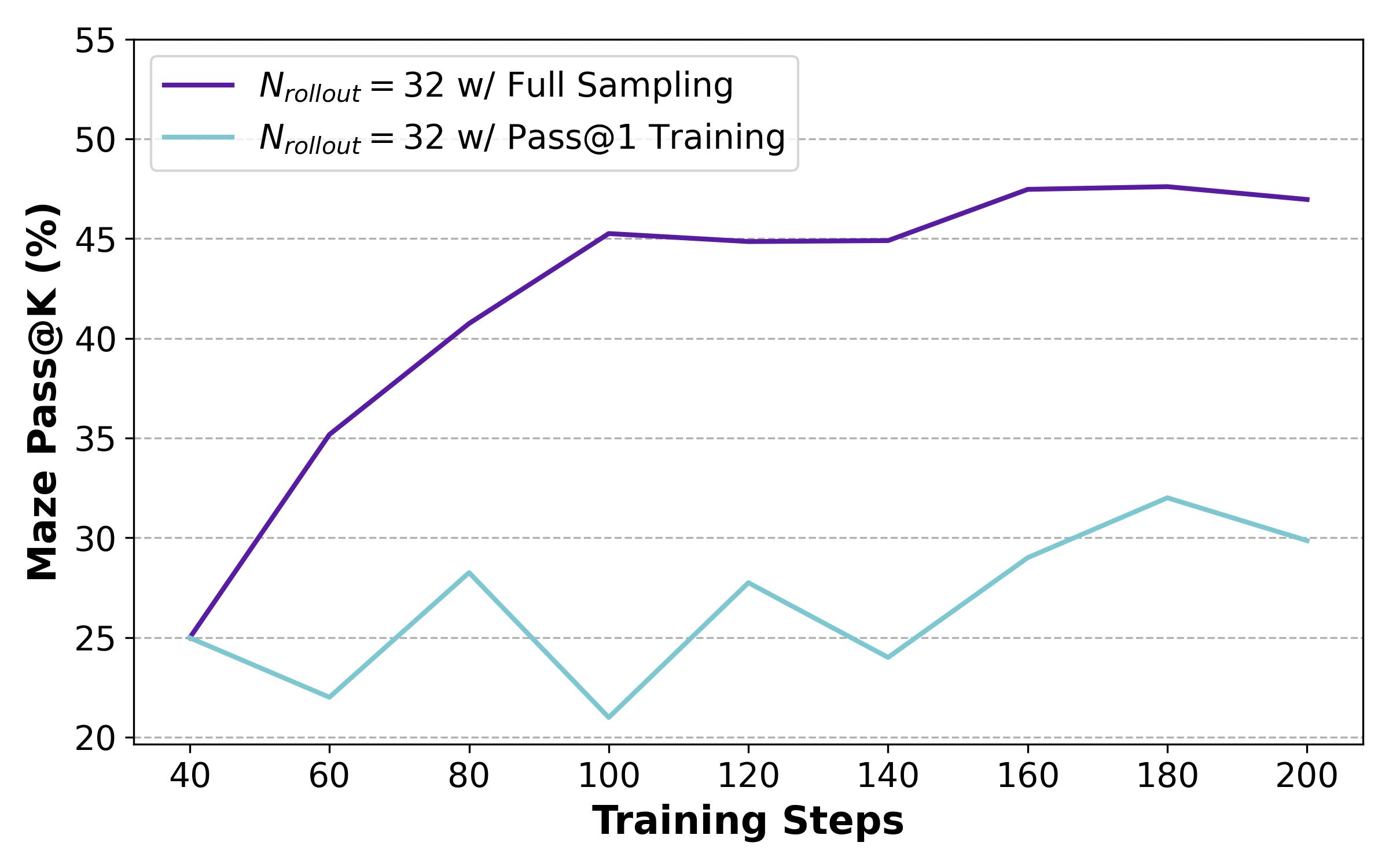
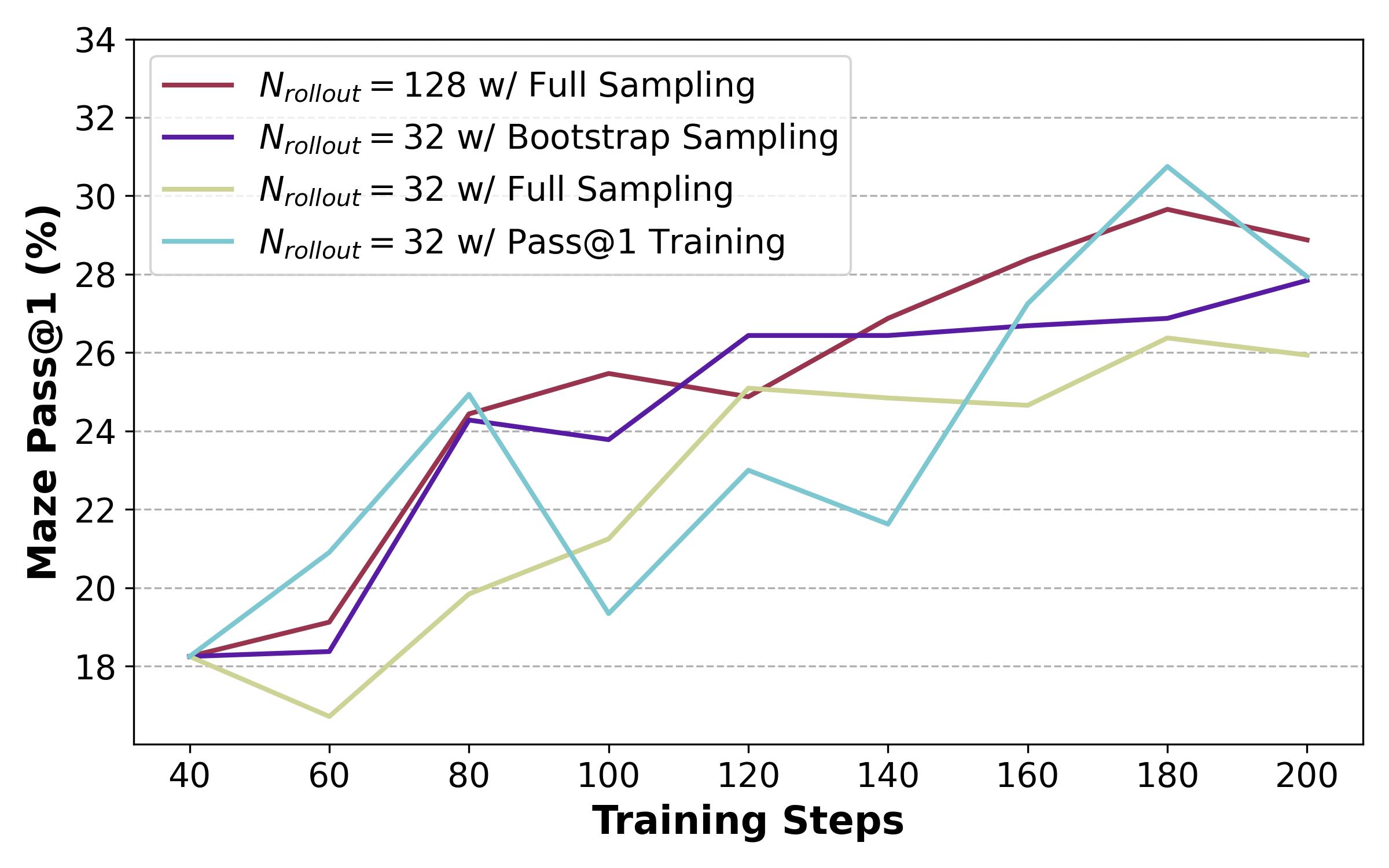
Bootstrap Sampling: Full Sampling虽然提高了性能,但计算量太大。为了减少推理次数,同时保持组数不变,采用bootstrap采样,先生成一个候选池,再从这个池子里面抽取k个答案,就形成了一组(这样允许某个答案被分到多个组里面重用),论文中候选池大小就和正常top1大小相同,也就是平均而言每个样本被重用k次
- 既然Bootstrap Sampling只不过是对样本的采样重用,那其实可以直接计算对应的优势值的期望,所以可以省去采样这一步,直接计算候选池中正负样本的个数,通过解析解得到期望带入计算
其他实验:
Pass@k的熵在训练中是上升的,而Pass@1后期会收敛,支持了前面的探索-利用论
k的值的影响?k的值不是跳出局部解的重要因素,但k值越大,优势越小(因为只有抽样全负才会是负奖励,k值越大正奖励概率越高),步长越小,训练效率降低,这个结论和也可以在改变学习率中得到验证
无论是小规模还是大规模的 LLM,都可以从 Pass@k 训练中受益。此外,模型架构和模型系列不会影响持续 Pass@1 训练的提升,下游任务的领域和形式也不会影响 LLM Pass@k 性能向 Pass@1 性能的迁移
分析:
同样是奖励从0到1,Pass@k的梯度出现在比Pass@1更早的地方(一次做对和K次做对),会使得Pass@k更倾向于解决更难的问题而不是中等难度的问题(由于Pass@k有一个argmax, 所以提高已经会做的�题的正确率的效果是不断减小的)
Pass@1
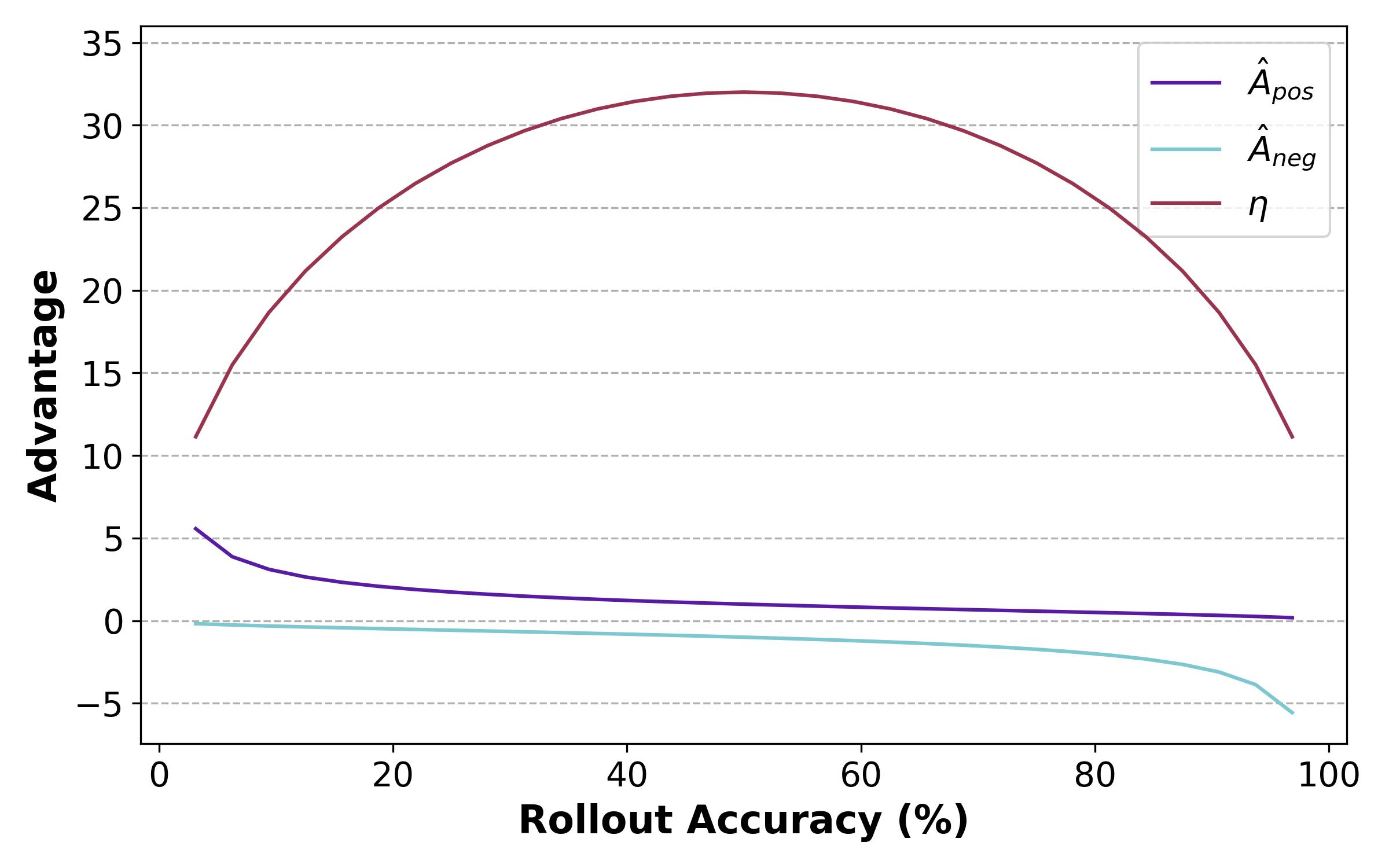
Pass@k
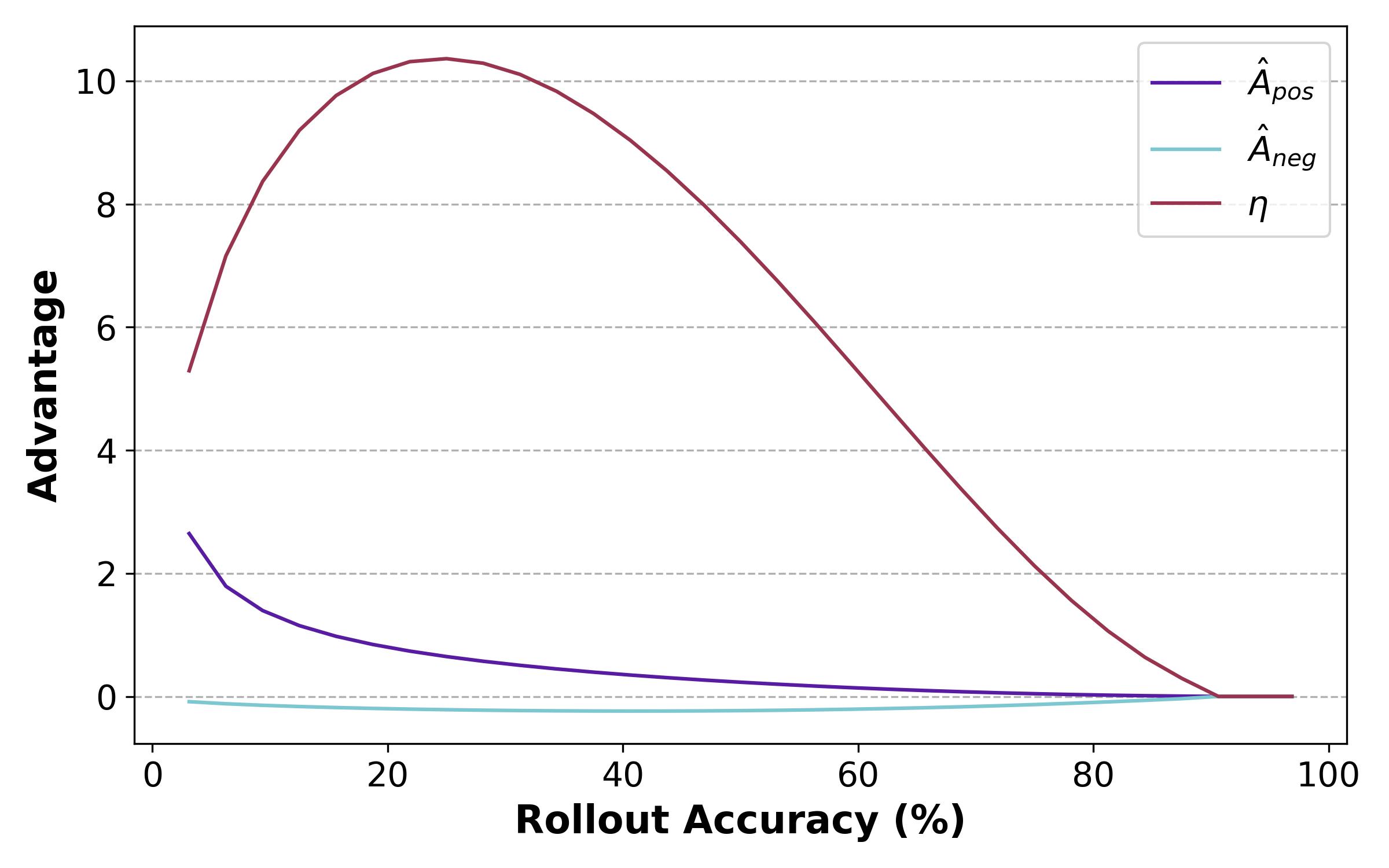
还做了一个对比试验是仅将简单问题的奖励设置为0,不能防止模型过度优化
为了分析是否全是梯度曲线峰值带来的影响,手动调整奖励曲线,设计了一个这样的曲线
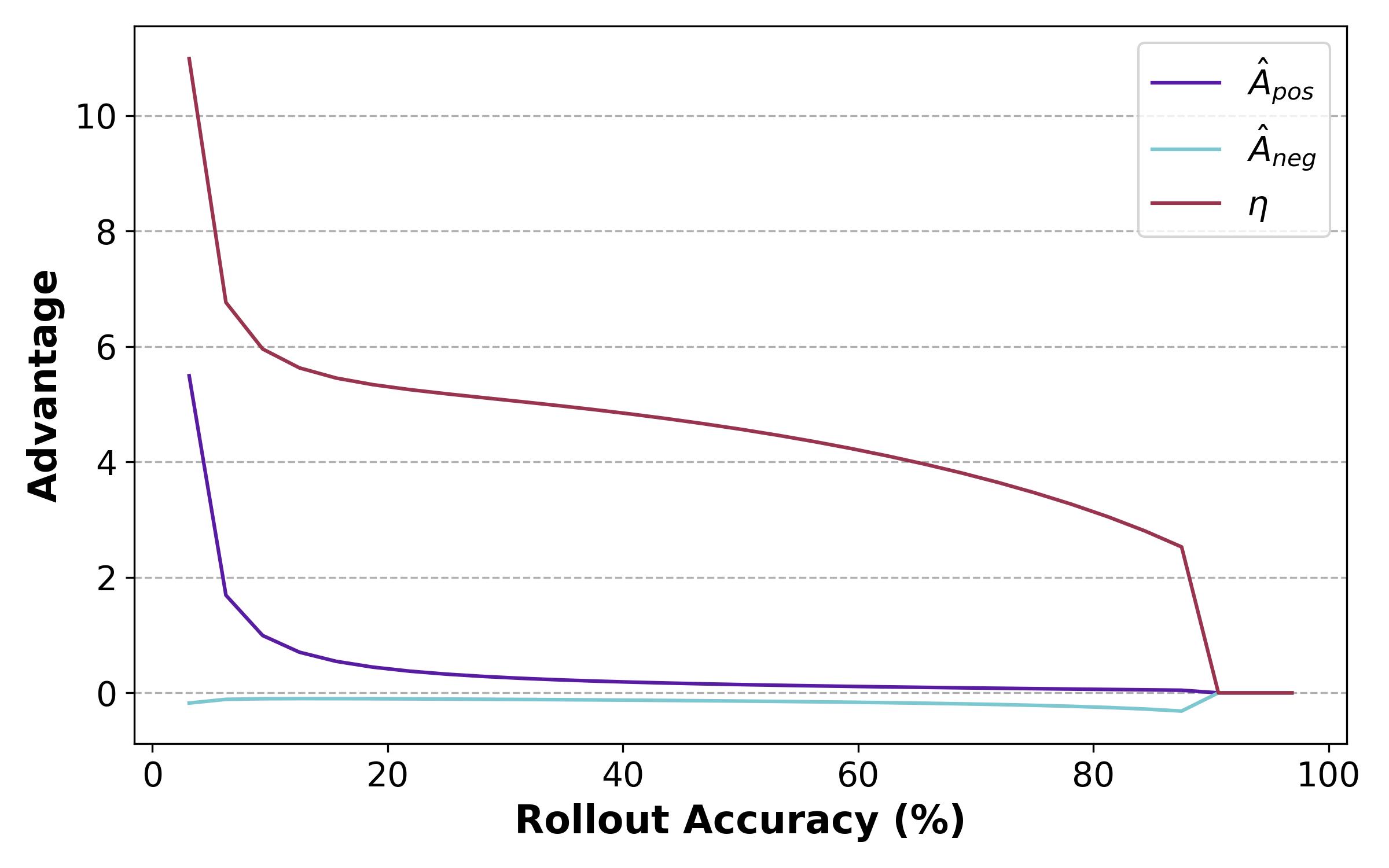
发现太注重困难的样本也不好,模型后期乏力
既然Pass@k 更注重困难样本,Pass@1 更注重一般样本,能否动态结合?
一个样本池中,正样本越多,越需要注重困难样本;反之需要先学会一般样本,因此设计了这样的优势函数
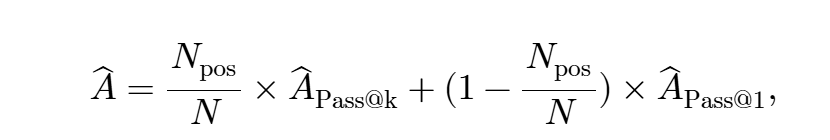
发现效果非常好
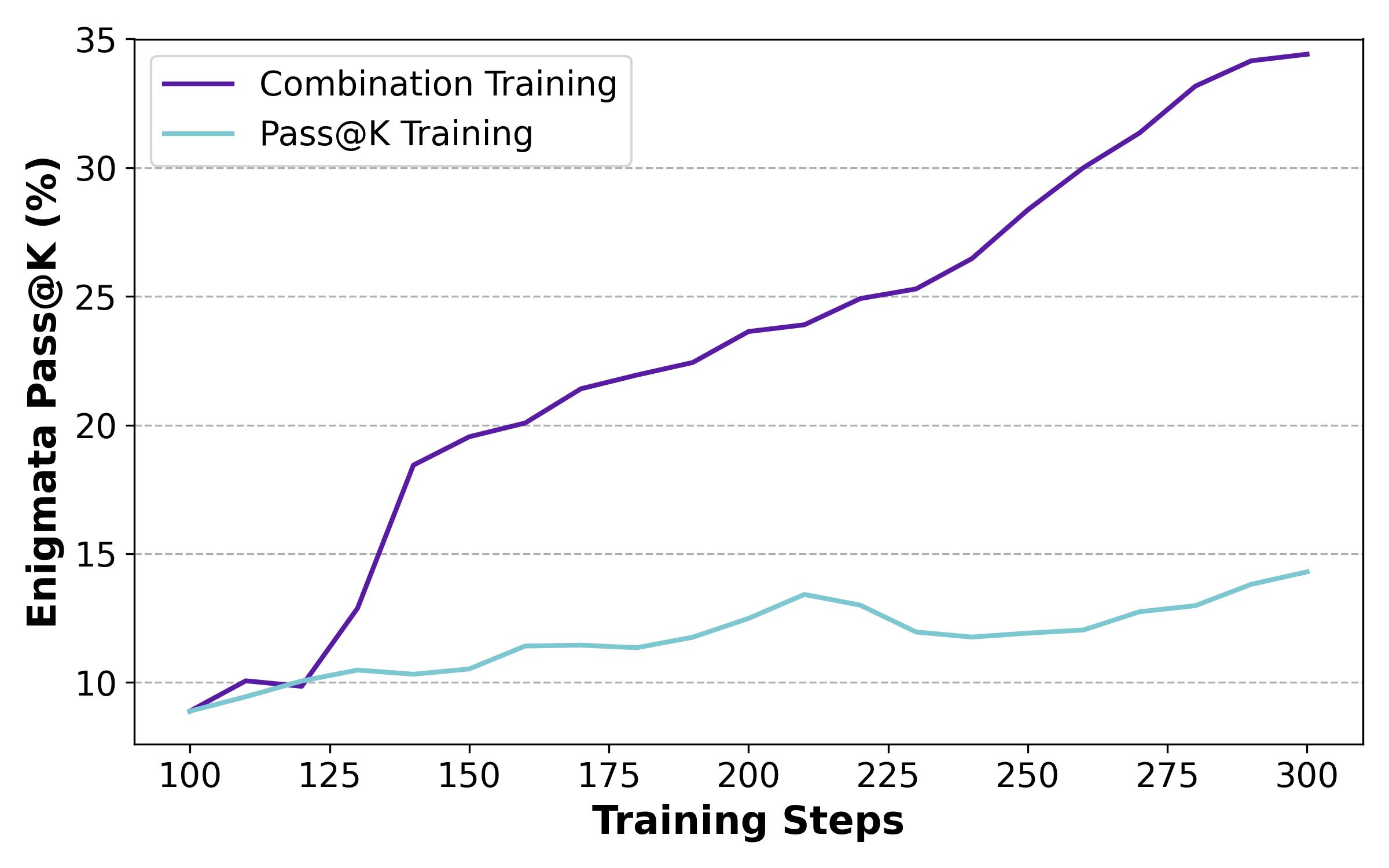
文章还做了另一个实验是,用熵而不是正样本数量来判断一个问题是否是困难的,熵高的50%认为是困难问题,使用Pass@1, 低的使用Pass@k,也得到了不错的效果
简评:感觉没太多好说的了,他们做的相当好,从最开始的发现topk training可以提升效果,再到用bootstrap sample提高效率,再到公式的推出,自然发现topk就是本质上对应的难度-奖励曲线的不同,再到设计相关的实验验证,最后提出简单的��自适应机制来结合Pass@1和Pass@k,也取得了相当好的实验效果,感觉挺一气呵成的,感觉是一个会成为范式的trick
Structure-Aware Fill-in-the-Middle Pretraining for Code
问题:现有的FIM将代码视为字符序列,而忽视句法结构

方法: 结合AST和FIM, 在训练时,被mask的部分始终是AST的一个或多个完整子树
代码解析:Tree-sitter
mask算法:涵盖不同的AST节点,提高泛化能力,且与具体语言无关
- 单节点mask: 按照对应文本的数量成比例抽样
- 多节点mask: 先进行一次字符区间的采样,再找到包含这个字符区间的最小3节点的AST子树,子树中再取和原始字符区间有最大交并比的部分
评估:字符级别困惑度,文章给出不用实际benchmark的原因是大规模单测太难。
简评:非常直接的想法,就类似word-level BERT对原始BERT的改进,不过它怎么构建AST的倒是可以参考。文章最后的评估用困惑度说服力不高,但考虑到它的数据量确实大(256*H100训练),也可以理解
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
问题:现有RL后训练存在策略熵减小导致模型快速收敛,后期探索较少难以提升的问题
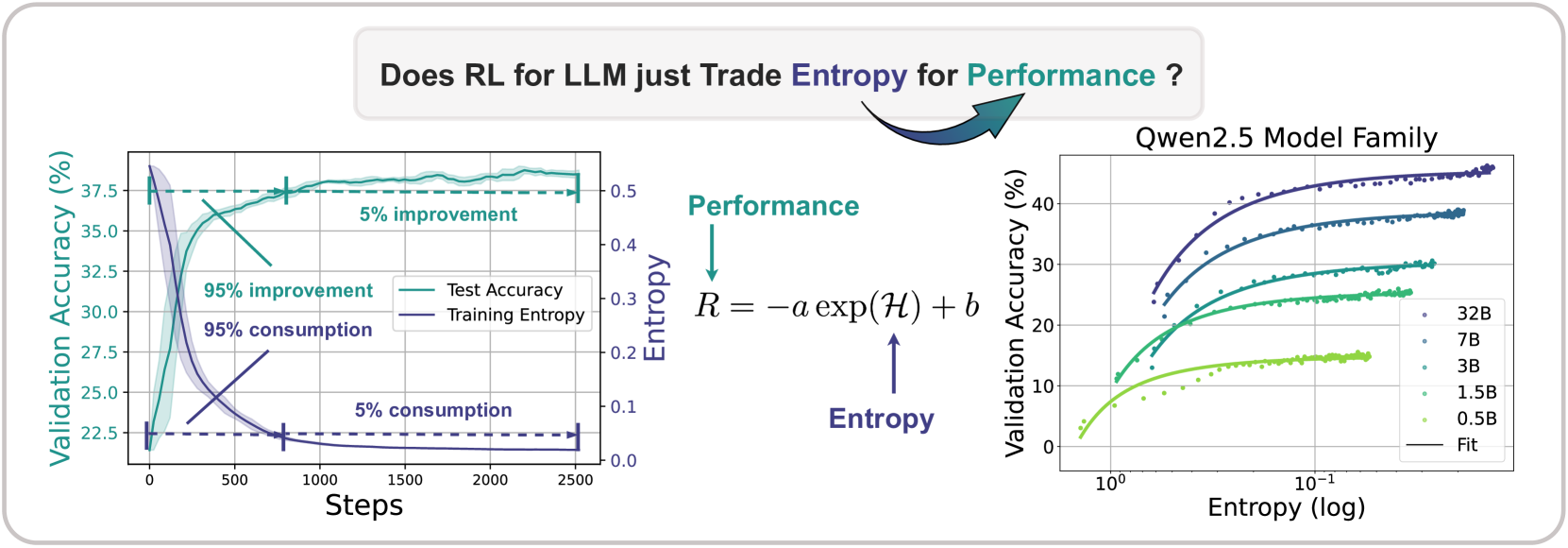
作者发现,在前1/3的epoch中,基本就已经达到了大部分的性能,而熵也进入低值,作者称之为熵崩溃"entropy collapse"
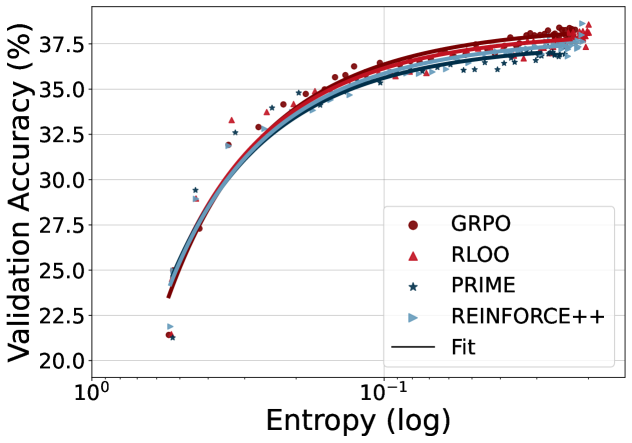
且对于不同的模型大小,对于不同的RL方法,都能拟合近似的定律
有了这样的拟合公式,可以在训练早期估计后期的性能,且ab与算法几乎无关,极限就是
另一个有趣的发现是,ab和模型大小呈对数线性关系
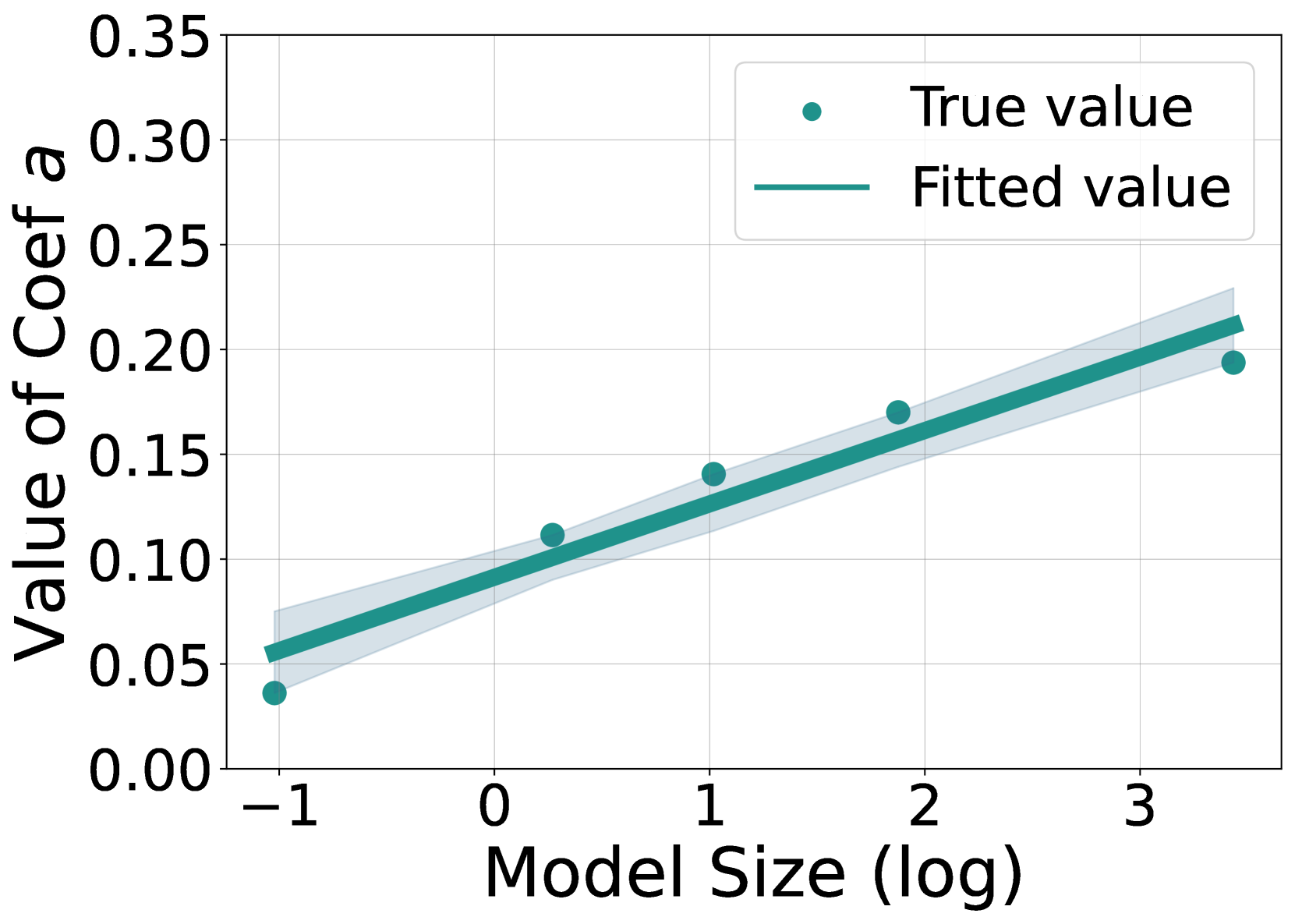
也就是说,不仅可以在训练前期拟合后期,还可以用小模型预测大模型的RL效果
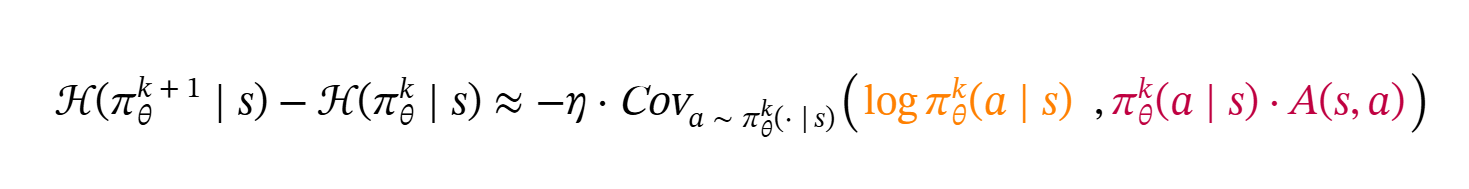
熵变公式如上,直观地讲,如果动作 a 同时获得高/低概率和高/低优势,则熵会降低,反之亦然
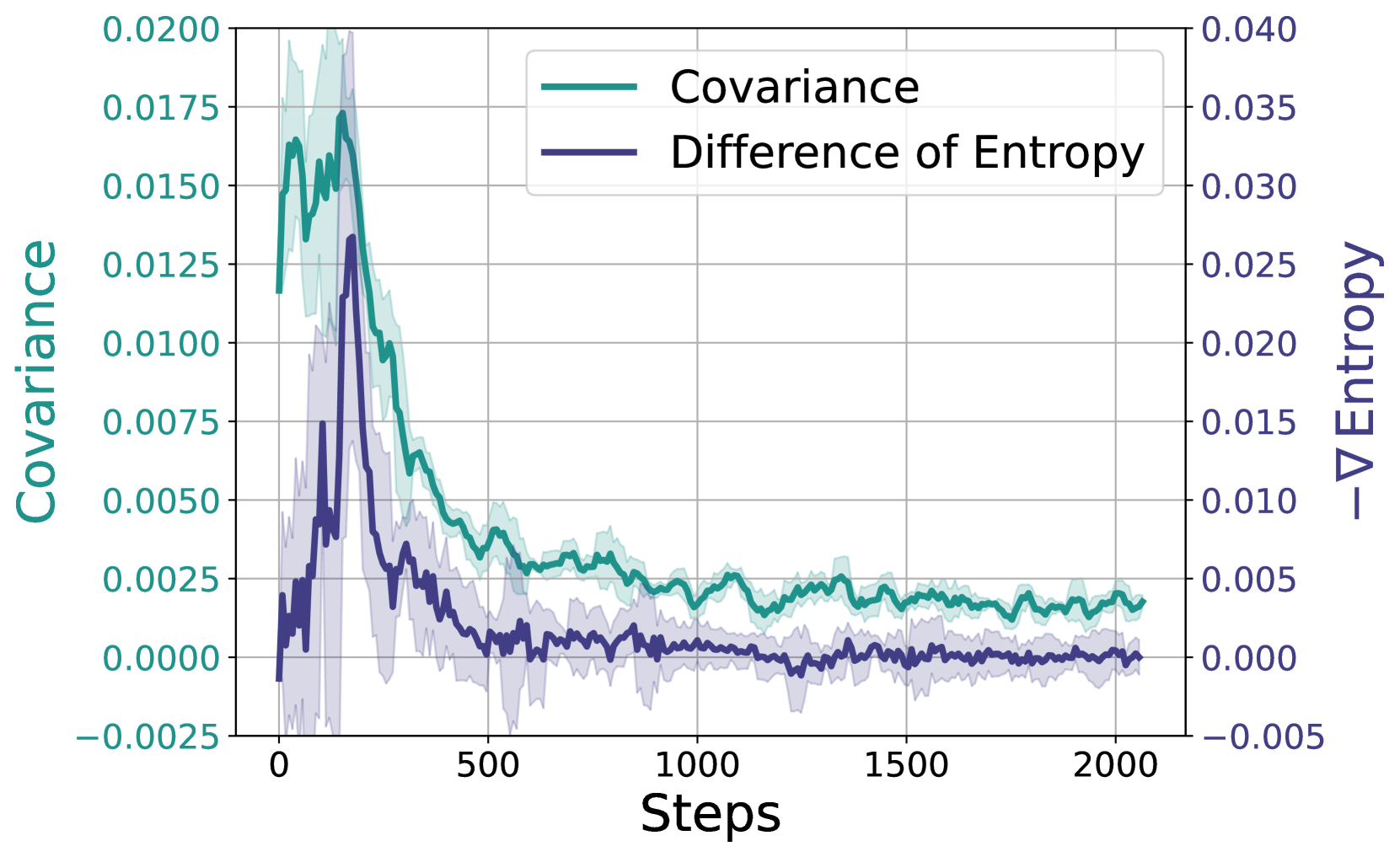
作者还提出,直接�使用熵损失的方法,如, 不仅对超参数敏感,实验效果也并不优于基线
所以作者提出的方法是,针对高协方差的一小部分token做Clip或者KL,就能防止熵崩溃,下面的实验结果也表现很好,熵后期不下降,回答长度增长,正确率大幅度提高

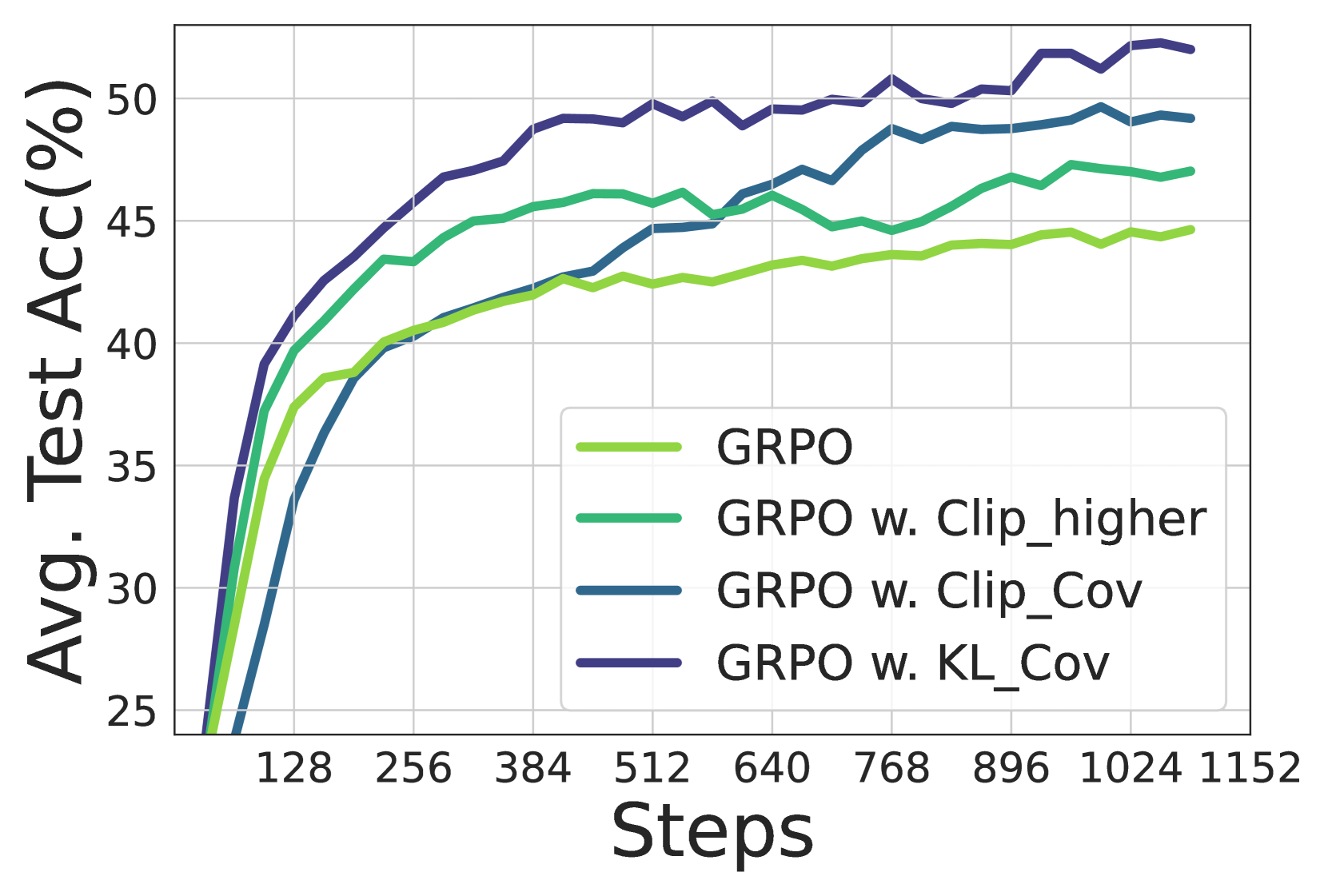
作者发现策略熵对超参数设置非常敏感。具体来说,我们的方法仅干预一小部分 token( 10−4 到 10−3 ),却完全改变了熵曲线。这意味着几个“关键” token 对 LLM 的熵至关重要
简评:搬运作者对clip-higher的讨论,作者认为,clip-higher也有类似的功能,提高重要性采样的上限会带来更多低概率的token,上限阈值仅影响具有正优势的 token,这意味着 clip-higher 实际上在梯度计算中添加了更多低协方差(低概率、高优势)的 token,所以结论殊途同归。而作者直接提出协方差是更胜一筹。
不过作者也说了现在还不清楚熵和模型性能的完整关系,也不清楚最优的熵值
另一个就是这些熵的论文主要还是在math任务上做的,code任务能否有相同的结论还是一个问题 (我认为这两个任务关键在于中间过程是不是重要的,math只有结果可能会得到一些错误的结论)
Improving LLM-Generated Code Quality with GRPO
问题:take code quality into consideration,不多赘述
方法:维护了一个库,把现有的一些评估代码质量的方案整合了起来(code complexity, dead code, code structure(linter等), style&doc, safety, performance...), 然后质量奖励和正确性奖励一起放到奖励里面丢给GRPO
简评:只是占坑的,很草率的方法(对于奖励参数的设定),定量结果也不足。
Enhancing High-Quality Code Generation in Large Language Models with Comparative Prefix-Tuning
问题:take code quality into consideration
方法:比较有新意,将Dynamic Prefix和代码质量结合起来了,并且是使用对比学习的方法做这个前缀
基于Pylint打分,构建了一套数据处理流水线标注大量高、低质量的代码对(相似度高,质量差距大,且都至少通过一项基本测试)
然后在微调Dynamic Prefix的的时候,加上一个排名Loss,希望模型倾向于生成高质量的样本。
里面的掩码是用difflib做的,目标是聚焦于差异的导致质量出现区别的token,而不要考虑重复的token
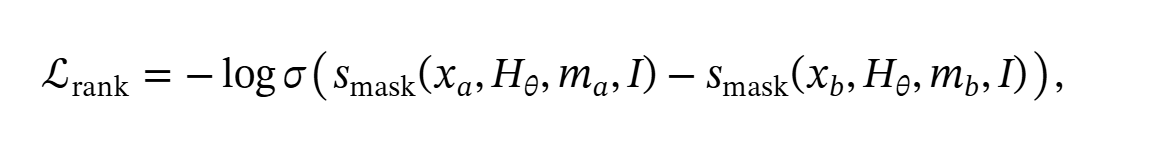
然后进行PEFT微调,再加上KL散度来保证不要丢失原始模型的代码生成能力
简评:这篇文章写得特别冗长,实验做的重点不突出,但思想是有意思的,并且明显可以继续挖,例如他们的代码相似度是简单的词频向量,自然挖掘出来的是细微处的代码风格问题,如是用index还是for each的形式遍历循环(只有这样的才会词频上高度相似)。但实际上是否可以用例如bge-code这样的代码语义嵌入呢?值得探究。
还有就是,这个数据收集的方法依赖于大语��料库,也只能挖掘常见的代码模式,如果用自生成的方法,例如假设我们已经有一些高质量的代码库作为ground truth,
用llm得到的补全片段当负项,也能构造正负样本对啊,既然都是训练得到一个通用的“code style prefix”,这样数据丰富程度能高很多。他们明显的数据少训练小(2*A6000*3h)。
Augmenting Large Language Models with Static Code Analysis for Automated Code Quality Improvements
问题:LLM refactor code没结合静态分析
方法:RAG + 静态分析软件 + Prompt 工程
简评:垃圾文章,真要做也是做一个能排序Code Quality的专用BERT,或者对现有的code embedder/reranker做adapter研究怎么把code quality调进去
A Hierarchical and Evolvable Benchmark for Fine-Grained Code Instruction Following with Multi-Turn Feedback
只需要看一张图就行了
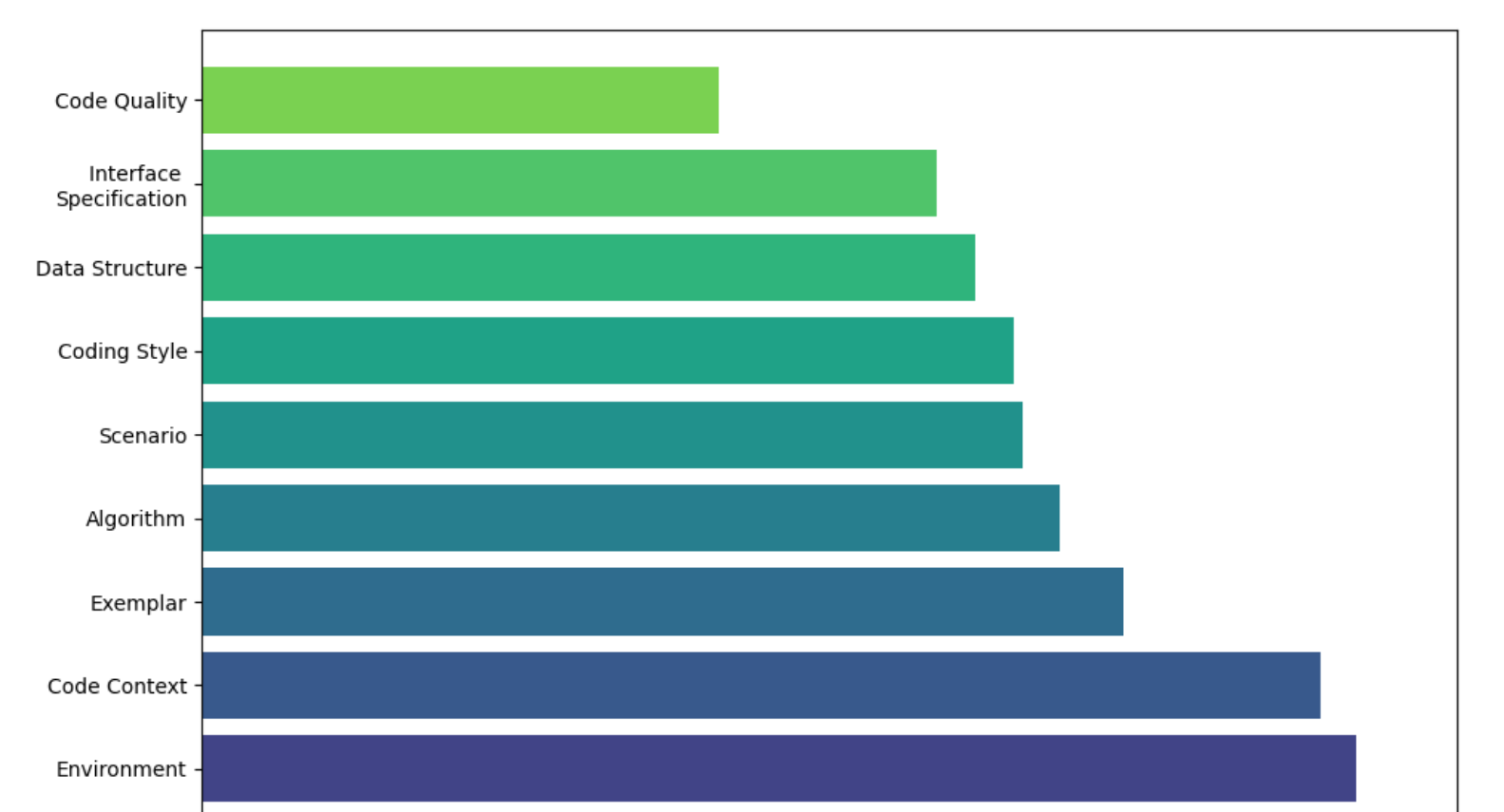
现有模型在约束生成时,quality这种抽象的约束是满足最差的
而对于多种约束的组合,现有LLM都很差
而对于有反馈的情况(例如linter之类),在3轮迭代左右就能有很大的提升,但后续再增加轮数也难以获得更高收益
Training Language Models on Synthetic Edit Sequences Improves Code Synthesis
问题:LLM这样“一口气生成所有代码”和先前的软件工程实践(增量式开发)是相悖的,而现在的code agent又需要增量开发的能力,有绕远路之感,于是研究能不能从预训练的数据侧上解决这个问题,即大规模合成 增量编辑数据
方法: 文章提出了一个LintSeq的方法,对于一段已有的代码,从里面修建某些部分回退,让回退后的代码不会触发linter错误,则构建了一个edit stage
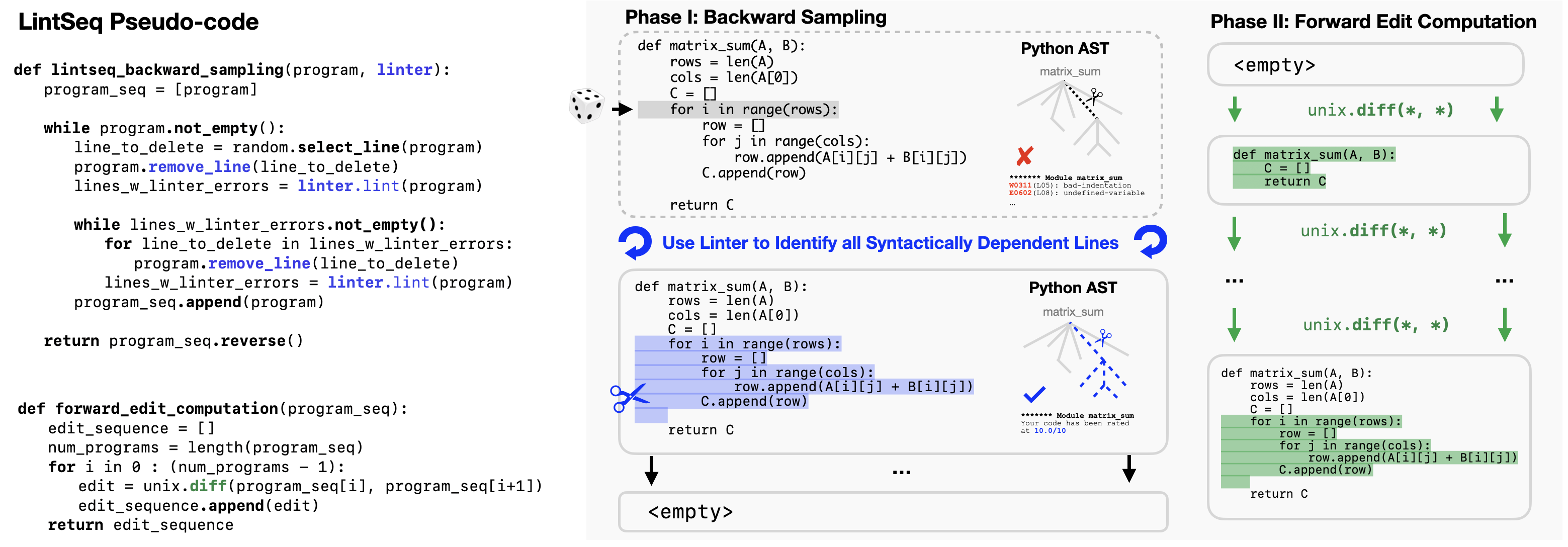
然后这样构建了数据集后自己SFT codellm,发现确有提升
简评:简单有效,或许可以想想这个怎么和RL结合?
Focused-DPO: Enhancing Code Generation Through Focused Preference Optimization on Error-Prone Points
问题:代码错误很多是中间的“易错点”出错,对于所有token一视同仁的奖励函数在代码任务上可能未必高效

方法:
- 该方法从真实代码库中提取概念,生成问题、代码和测试
- 由于有了测试,所以可以比较不同的生成代码的相对性能
- 通过共同前缀和共同后缀,得到中间不一样的中缀,就认为是“易错点”
然后DPO专注这一块的优化
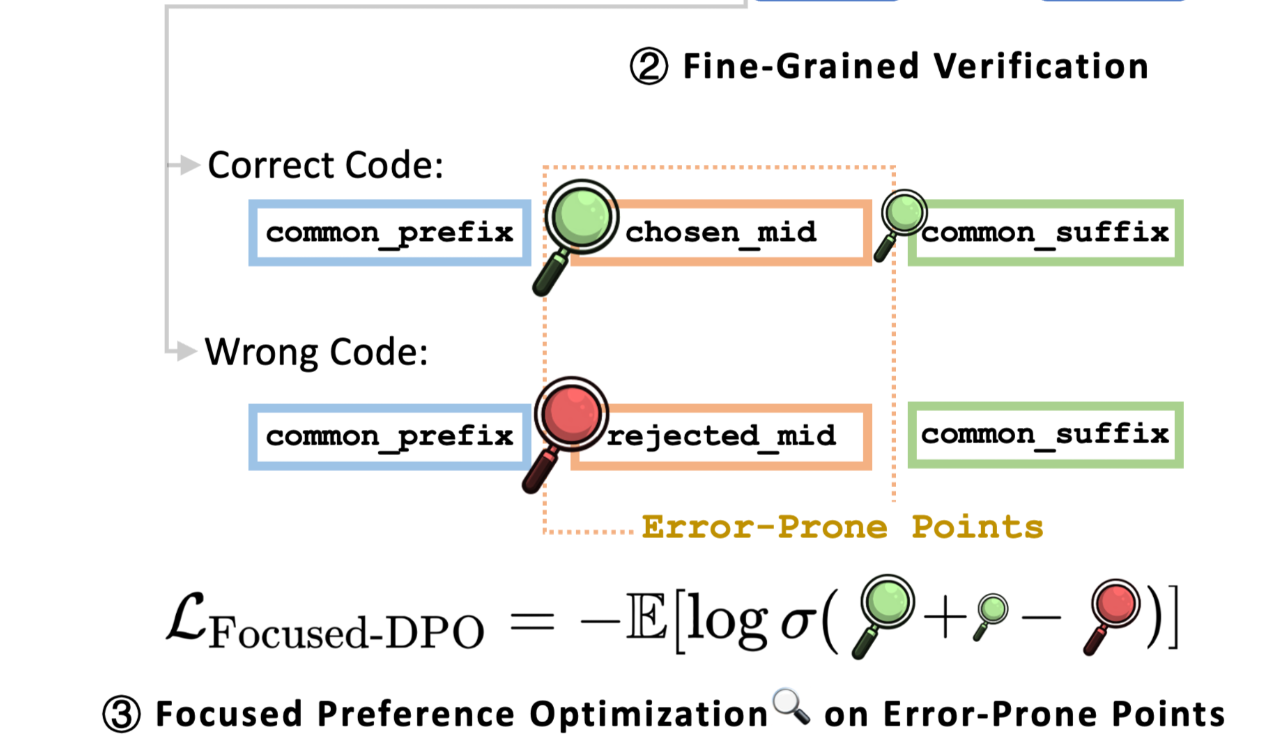
简评:感觉上是更软件工程的熵方法的简化,感觉这个易错点是能从LLM自身状态或者其他软件工程分析技巧中得到的,从前面几篇也可以看出,现在这种广义上的RL ”attention“ mask类工作越来越多了
这个方法要求生成测试,实际生产中感觉并不可用;抛开这个不谈,感觉就单纯对一个大型代码数据集,去分析里面的编码模式,找到相对少的n-gram,或者AST level迅速变化的地方作为易错点重点训都或许可行